
【学术科研】处理器芯片全国重点实验室四篇论文获MICRO 2024录用
在2024年的体系结构领域顶级会议MICRO (IEEE/ACM International Symposium on Microarchitecture ,CCF-A类)上,中国科学院计算技术研究所处理器芯片全国重点实验室(以下简称“实验室”)四篇论文《Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM》《Cambricon-M: a Fibonacci-coded Charge-domain SRAM-based CIM Accelerator for DNN Inference》《Cambricon-C: Efficient 4-bit Matrix Unit via Primitivization》《TMiner: A Vertex-Based Task Scheduling Architecture for Graph Pattern Mining》获录用。
论文《Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM》的第一作者为实验室硕士生于钟凯。Cambricon-LLM是首个支持70B规模大语言模型在边缘端设备上部署的加速架构。在智能手机和机器人等边缘端设备上部署先进的大型语言模型增强了用户数据隐私性并降低了对网络连接的依赖性,然而这项任务表现出计算批次小(通常为1)和计算强度低的特点,给有限的边缘资源带来了内存占用和带宽需求双重挑战。为了解决这些问题,Cambricon-LLM设计了一种基于芯粒技术,集成了NPU和专用的NAND闪存芯片的混合架构。首先,Cambricon-LLM利用NAND闪存芯片的高存储密度来保存模型权重,并为NAND闪存芯片增加了die内计算和die内纠错能力以在维持模型推理精度的前提下缓解带宽压力。其次,Cambricon-LLM结合了硬件感知的切片技术,使得NPU与闪存芯片协同进行矩阵运算,达到硬件资源的合理利用。总体而言,Cambricon-LLM比现有的闪存卸载技术快22倍到45倍,展示了在边缘设备上部署强大LLM的潜力。
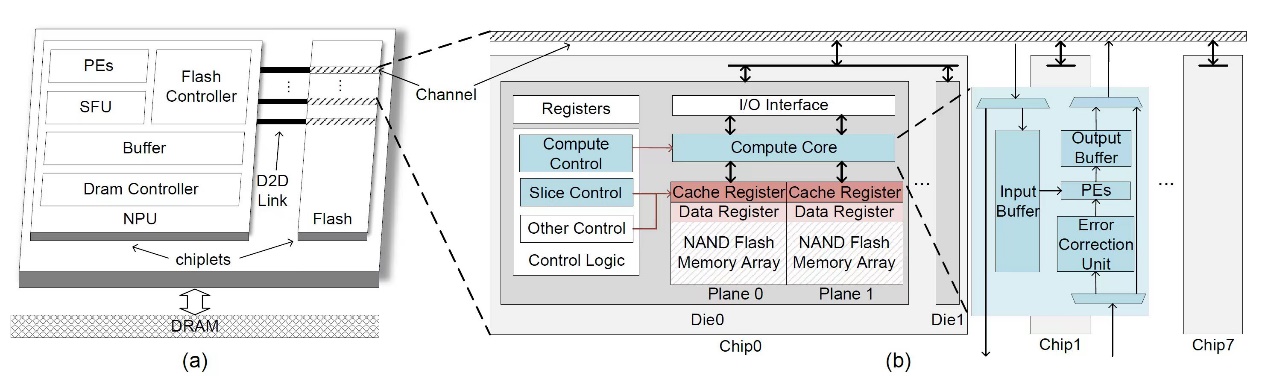
图1. Cambricon-LLM架构图
论文《Cambricon-M: a Fibonacci-coded Charge-domain SRAM-based CIM Accelerator for DNN Inference》的第一作者为实验室博士生郭泓锐。Cambricon-M是一种基于斐波那契编码的电荷域SRAM存算一体体系结构。存算一体结构减少了计算单元与内存之间的数据搬运,具有广泛的应用前景,其中,电荷域SRAM存算一体架构成为近年的研究热点。研究发现,模数转换器(ADC)的输入电压(即SRAM阵列的输出电压)动态跨度范围大,需要高分辨率ADC将高精度模拟电压转换为高位宽数字域数据,以避免精度损失,然而,高分辨率ADC逐渐成为能耗瓶颈(占比高达64%),限制了电荷域SRAM存算一体架构的发展。Cambricon-M采用斐波那契编码,保证输入中每个‘1’的相邻两位都为‘0’,降低操作数中‘1’的密度,以缩小SRAM阵列输出电压(即ADC的输入电压)的跨度范围,从而能够在电荷域SRAM存算一体架构中使用低分辨率ADC,降低能耗并减少精度损失。此外,Cambricon-M利用比特级稀疏等多种技术来解决高位宽斐波那契编码引入的额外能量和面积开销。实验结果表明,Cambricon-M将ADC能耗降低了68.7%,相比现有的数字域和电荷域加速器分别获得了3.48倍和1.62倍的能效提升。
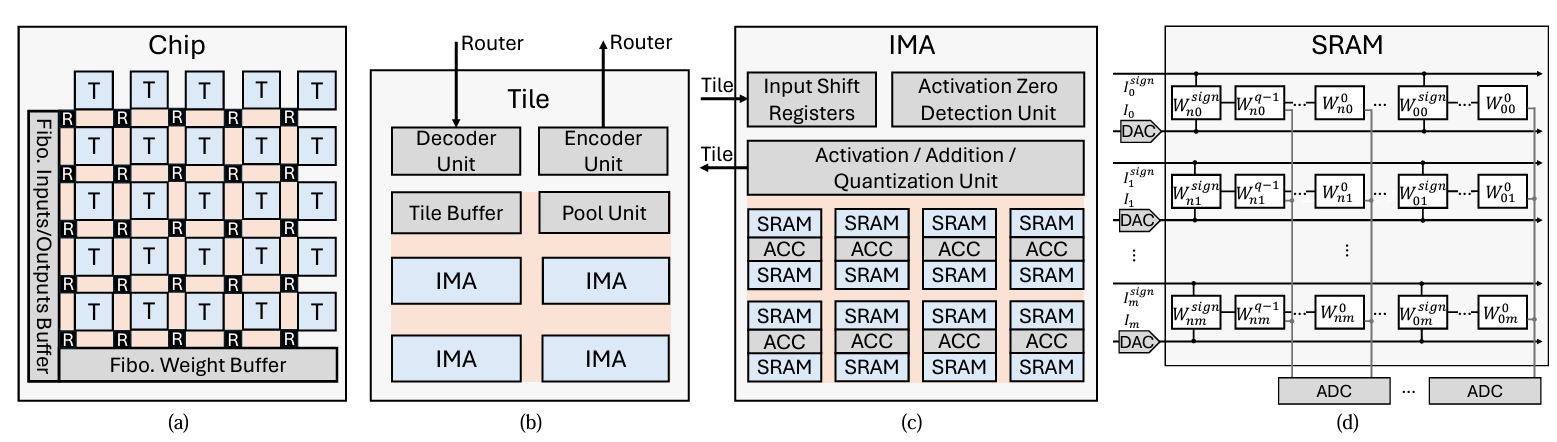
图2. Combricon-M架构图
论文《Cambricon-C: Efficient 4-bit Matrix Unit via Primitivization》的第一作者为实验室硕士生陈亦。Cambricon-C是一种处理低精度矩阵乘的加速器设计。深度学习常使用低精度数据格式应对日益增长的模型规模,以降低模型部署的硬件开销。但随着数据精度的降低,基于乘加的矩阵乘单元功耗收益率逐渐放缓,严重受限于重复的低精度数值乘法和高位宽数值加法。针对这一问题,Cambricon-C原始化矩阵乘算法,将乘加运算还原为一元运算——累加,利用四分之一乘法优化原始矩阵乘算法,避免重复的乘法运算,降低加法硬件的强度,获得实际收益。Cambricon-C脉动阵列相比基于乘加单元的脉动阵列有约1.95x的功耗节省,完整的Cambricon-C加速器相比传统TPU加速器,在处理量化神经网络时有1.13 - 1.25x的功耗节省。
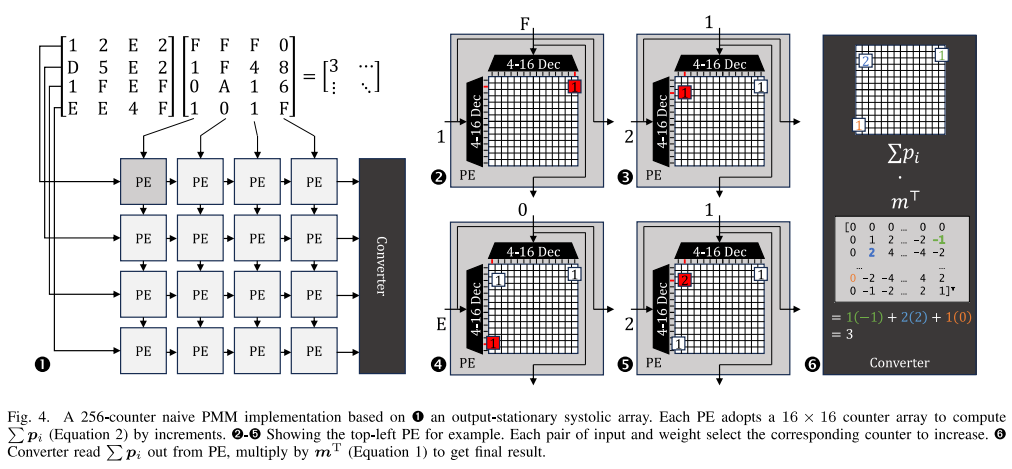
图3. Cambricon-C示意图,使用256个计数器实现的原始化矩阵乘硬件基于:1. 输出固定(output-stationary)脉动阵列;2-5. 每对激活和权重会触发相应的计数器进行累加;6. 通过计数器的记录值与预计算的查找表计算最终结果。
论文《TMiner-A Vertex-Based Task Scheduling Architecture for Graph Pattern Mining》的第一作者为实验室博士生李泽润。TMiner是一个基于近存计算技术的图模式挖掘加速器。图模式挖掘用于搜索与给定模式同构的子图,被广泛应用于生物信息学、网络安全、社交网络分析等领域。现有的图模式挖掘系统存在多个层次的冗余访存:1、多个计算单元同时访问相同的数据,造成冗余的DRAM或Last Level Cache访问,并降低Cache的有效容量;2、同一个计算单元在离散的时间里反复访问同一个数据,造成冗余的DRAM访问;3、一个计算任务将对一个完整集合的访问拆分为对多个子集的访问,既造成冗余的DRAM访问,又破坏了访存的连续性。TMiner在设计阶段依据访存行为对任务进行划分,使得不同计算单元的访存互不相交,消除了计算单元间的冗余访存;在编译阶段将对多个子集的访问合并为对超集的访问,消除了任务内的冗余访存;在运行时将具有相同数据需求的任务合并执行,消除了计算单元内的冗余访存。通过上述优化,TMiner在不损失并行度的情况下,消除了大量的冗余访存,在社交网络、通信网络等数据集和多种模式的评估下,可以实现平均3.5倍的性能提升。
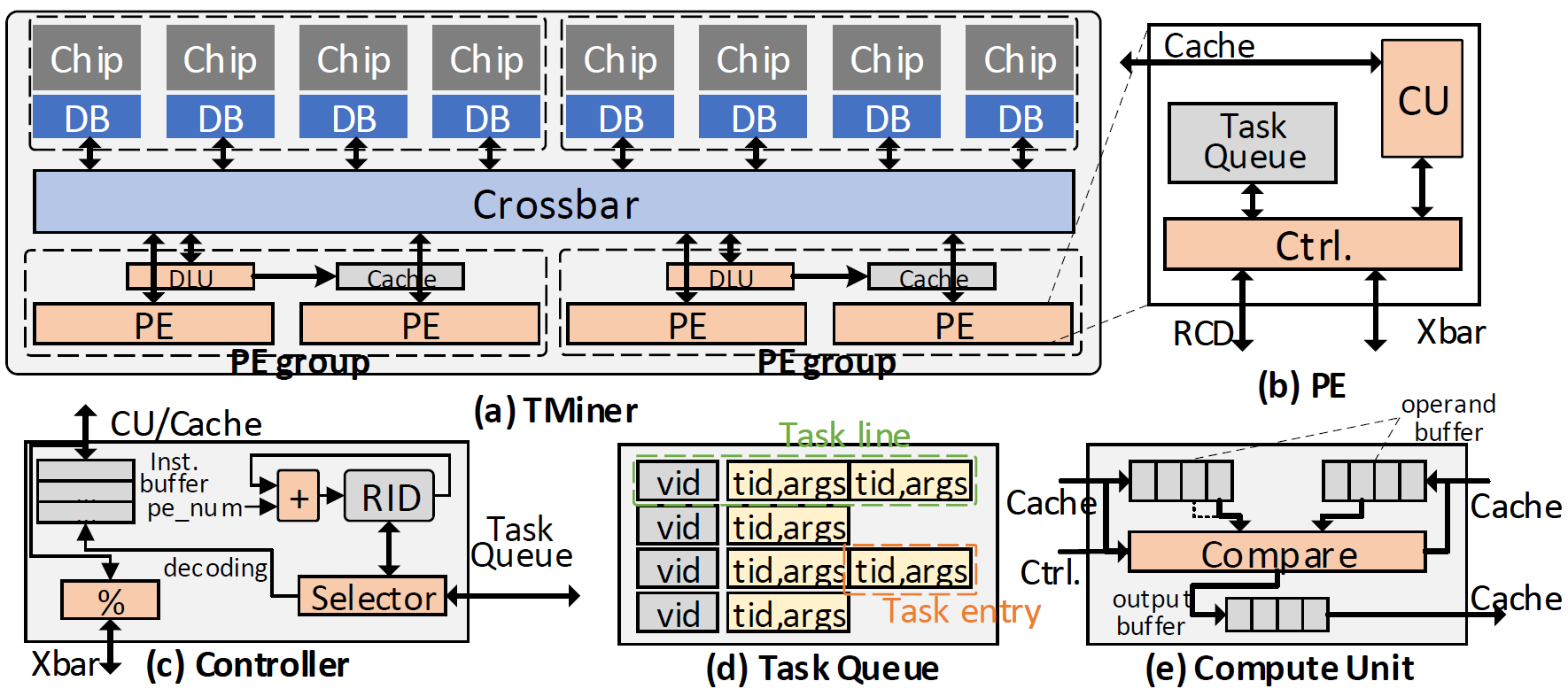
图4. TMiner硬件架构。(a) 整体架构,(b) PE架构,(c)控制器设计,(d)任务队列设计,(e)计算单元设计。
此外,实验室与上海交通大学合作的论文《SRender: Boosting Neural Radiance Field Efficiency via Sensitivity-Aware Dynamic Precision Rendering》亦被MICRO录用。SRender首次将传统图像渲染使用的自适应渲染技术迁移到神经渲染,提出了一套基于数据敏感性的可变精度量化方案,并针对板块冲突问题提出了一种粗细粒度结合的数据重排机制,实现了56FPS的实时渲染效果。
MICRO会议主要收录微架构、编译器、芯片和系统相关领域的研究进展。自1968年首次召开以来,MICRO已成为计算机体系结构领域的顶级会议,是全球计算机体系结构领域最为重要的学术会议之一,对于推动该领域的研究和发展起到了至关重要的作用。本届会议共收到497篇投稿,录用113篇,录用率为22.7%。