
从技术体系视角看研究所科研布局
一、 建立计算技术体系的动机
计算所高举自主创新大旗发展国产处理器20年了,依然没有完成国家在处理器芯片上的战略目标。过去的方式是单点突破,但是遇到了一些卡点,比如龙芯CPU遇到了Wintel生态卡点,寒武纪NPU遇到了NVidia生态卡点,海光CPU遇到了先进工艺卡点。所以,处理器难的不是做出一款芯片,或者实现一个技术指标,而是处理器生态怎么构建,技术体系怎么可控。生态的背后是有技术体系做支撑的,需要学术界发挥作用。分析目前几大主流生态,都是几大部分勾连在一起,才建立起一个技术体系,比如:Wintel体系是Windows OS、Intel CPU、IDM制造互相勾连,AA体系是Android OS、Arm CPU、Foundry制造互相勾连,iPhone体系是Mobile技术、掌上PC、Industry Design互相勾连,Intel DC体系是Xeon CPU、PCIe/SATA控制器等IO标准、Linux开源软件互相勾连,现在计算所在做的香山处理器也是试图把开源芯片、Minjie设计工具、Chiplet制造互相勾连起来。技术体系比芯片单个技术更重要,只有通过建立起技术体系才能解决处理器目前的困境。
二、 建立处理器的三个技术体系
从构建处理器生态的道路这个角度,可以把我国自主创新的处理器技术体系归纳成A、B、C三条发展道路。A体系为高铁模式,我国信息化的主流平台被X86、ARM生态所占领,海光、海思、飞腾等国产处理器的道路强调“全兼容”,浮点增强、可信计算、集成芯片等是其中控制点技术。B体系为北斗模式,这个道路强调“全自主”,以龙芯和申威为代表,不跟市场主流兼容,需要把国外控制生态上的大量应用迁移上来,自主指令集、操作系统层软硬协同优化、应用迁移等是其中控制点技术。龙芯公司计划在2035年建成独立的技术体系及生态控制点。C体系为5G模式,走“全开放”的道路,即技术体系自主创新,关键技术开源开放,全世界一起来建生态,生态价值全球共建共享,香山(睿芯/平头哥/奕斯伟/算能)等RISC-V、寒武纪NPU、中科驭数DPU就是走的这条道路,敏捷设计的RISC-V开源处理器、NPU/DPU芯片是其中的控制点技术。
三、 智能时代的计算技术新体系
可以把计算技术的学科体系分成7层,第1层是电路,第2层是处理器,第3层是计算设备,第4层是计算系统,第5层是网络,第6层是处理算法,第7层是计算应用。按照7层,总结一下过去40年计算所的科研成果代表作:第1层有集成电路测试、验证与容错方法,第2层有龙芯CPU、寒武纪NPU,第3层有联想PC,第4层有曙光HPC,第5层有中关村科研试验网,第6层有AVS视频编解码与计算视觉算法,第7层有国家网络关防、舆情与情报重大应用。这些各层的科研成果在层间关联性很弱,几层之间的关键技术之间并没有勾连在一起,属于弱技术体系。
未来网络空间的重大变化是算力将基础设施化,可以从算力(Computility)的新视角来重新描述计算技术层次体系:第1层是算力组件,第2层是算力部件,第3层是算力设备,第4层是算力站,第5层是算力加工网,第6层是算力加工方法,第7层是算力应用。
在智能时代,计算技术将会出现新的技术体系,把计算所现在和未来要做的重大科研方向按照上述7层进行归纳的话,即第1层是集成芯片设计方法,第2层是C体系处理器,第3层是物端计算机,第4层是高通量智能计算系统,第5层是信息高铁算力网,第6层是大数据分析与AI算法,第7层是数据与智能驱动的重大应用。未来这些分布在不同层的重大科研成果能不能关联起来,通过层间关联构成强技术体系?依托这个强技术体系,能不能支撑我国打开新的全球化之路?
下面分别论述这7层中的重大科研方向。
1.集成芯片设计方法
第1层是集成芯片设计方法,是支撑C体系处理器设计的方法与新组件。C体系处理器面临的挑战是尺寸微缩技术道路受限,我国的先进工艺受限,需要在复杂芯片设计方法进行变革,从堆叠法变成构造法。构造法包括分解、组合、集成制造三部曲,重点要从集成电路变到集成芯片(分解);从IP变到芯粒(组合);从2D变到3D(集成制造)。其中,集成芯片设计需要新EDA工具,集成芯片需要互联标准,集成芯片需要基本型芯粒。还需要研制一些创新的非冯/非硅的算力组件,包括存算一体组件、超导计算组件、光子计算组件、量子计算组件等。
2.C体系处理器
第2层是C体系处理器,为上层的物端计算机和高通量智能计算机系统提供处理器芯片。按照“以快打慢、以多打少”的技术理念,C体系处理器的技术路径如图1所示,其中作为参照物,右边列出了软件成功的设计方法。如果能构造出这样一套技术体系,就形成了跟X86、ARM很不同的一套新技术体系。
|
|
处理器 |
软件 |
|
指令集 |
开源硬件基金会(OSH) |
开源软件基金会(OSS) |
|
虚拟化 |
体系结构虚拟机 (CVM) |
虚机技术(KVM/JVM/Docker) |
|
体系结构 |
面向对象体系结构与构件(OOA) |
面向对象语言与构件(OO) |
|
IP核 |
处理器敏捷开发流程与验证工具(Agile) |
云函数(Serverless) |
|
芯粒 |
集成芯片(Chiplet) |
微服务(Micro-service) |
|
SoC芯片 |
AI辅助设计与云平台(PDA/Design Cloud) |
服务(Service) |
|
制造 |
设计-制造一体化 (IDM2.0) |
开发-部署一体化(DevOps) |
图1:C体系处理器技术路径
计算所当前与C体系处理器相关的科研工作,包括:香山RISC-V开源CPU核、睿芯RISC-V高通量CPU、寒武纪NPU、睿芯高通量DPU和驭数网络DPU、处理器敏捷开发工具、处理器AI辅助设计平台 (PDA)、体系结构虚拟机(CVM)。
3.物端计算机
第3层是物端计算机,作为上层的算力网原生应用的客户端,作用相当于智能手机是移动互联网原生应用的客户端。计算系统的发展趋势是从固定终端和后台的计算/数据中心,到移动终端和后台的云计算中心,再到泛在终端和后台的算力网。泛在终端的研究内容覆盖很广,包括传感器、物端计算机、泛在OS、物联网、AIoT应用等。
下面罗列计算所在开展的一些相关工作,比如:关键传感器方向有海洋温盐传感器、全光陀螺仪;物端计算机方向有工智机(注:一种算控融合的工业控制计算机)、弹载/星载/机载/舰载/车载专用智能计算机、物栖IoT计算机(包括物端芯片、硬币机、物端OS、冒泡软件组成“物栖四件套”);关键泛在终端方向有第三代智能农机 (还包括主粮种植模拟器、黑土地保护性耕作信息系统)、非结构化环境自动驾驶车(应用场景有西部高原运输车和火星探测车)。
4.高通量智能计算系统
第4层是高通量智能计算系统,作为上一层信息高铁算力网的新一代算力站。包括三个方向,分别是非图灵计算模型、基于第三代机群架构的高性能计算机和智能计算机。非图灵计算模型有Ising计算模型(面向高维组合优化问题〔NP-hard〕的近似解)、量子图灵机计算模型等。第三代机群架构高性能计算机又包含了三个不同系统,其中:高通量计算系统布局了高通量CPU/DPU、高通量的网卡/存储系统等技术点;高安全等级云主机布局了内存强安全防护、加固VEE /VMM/Linux、密态计算加速器等技术点;10EF级智能超算系统布局了科学智能建模方法(HPC+AI)、高性能互联网络/光互联网络、OODA智能编程框架等技术点。
第三个方向是智能计算机。从计算的视角理解,智能的本质就是求解复杂问题的能力。智能计算机是支持用符号主义(知识工程与专家系统)、连接主义(神经元网络)、行为主义(OODA环)的方法高效求解复杂问题的通用计算机。HPC求解问题的规模大,但不等于复杂,而小规模的三体问题却是一个复杂问题,虽然只有三个主体,它们相互作用力与轨迹的问题用性能很高的高性能计算机都求解不了。现在HPC+AI方法就是对于物理系统里的比如量子态、电子运动等复杂过程,用数据拟合的方法化解成一个简单问题进行求解。求解复杂问题,是智能计算机与高性能计算机的本质区别。当前对智能计算机的探索还是非常的初级。

图2:数据与智能驱动的科学发现范式
数据与智能驱动的科学发现范式是高性能计算发展的主要驱动力。科学发现范式的变迁如图2,第一范式是科学实验,依赖“大装置”;第二范式是科学理论,依赖科学家的“大脑袋”;第三范式是科学计算,依赖“大机器”;第四范式是科学数据,依赖“大数据”;第五范式是科学智能,依赖“大实验”。后边三个范式都是用信息技术赋能科学发现,恰好对应信息化的三个阶段——数字化、网络化和智能化的阶段。第五范式的目标就是求解更复杂的问题,它的基本思路是用AI、大模型提供求解高维问题的快速算法,同时将科学家大脑与知识(人)、计算模型与算法(机)、实验数据(物),在一个信息空间里打通信息流、工作流,从而支撑科学发现过程高效地快速迭代与演化。
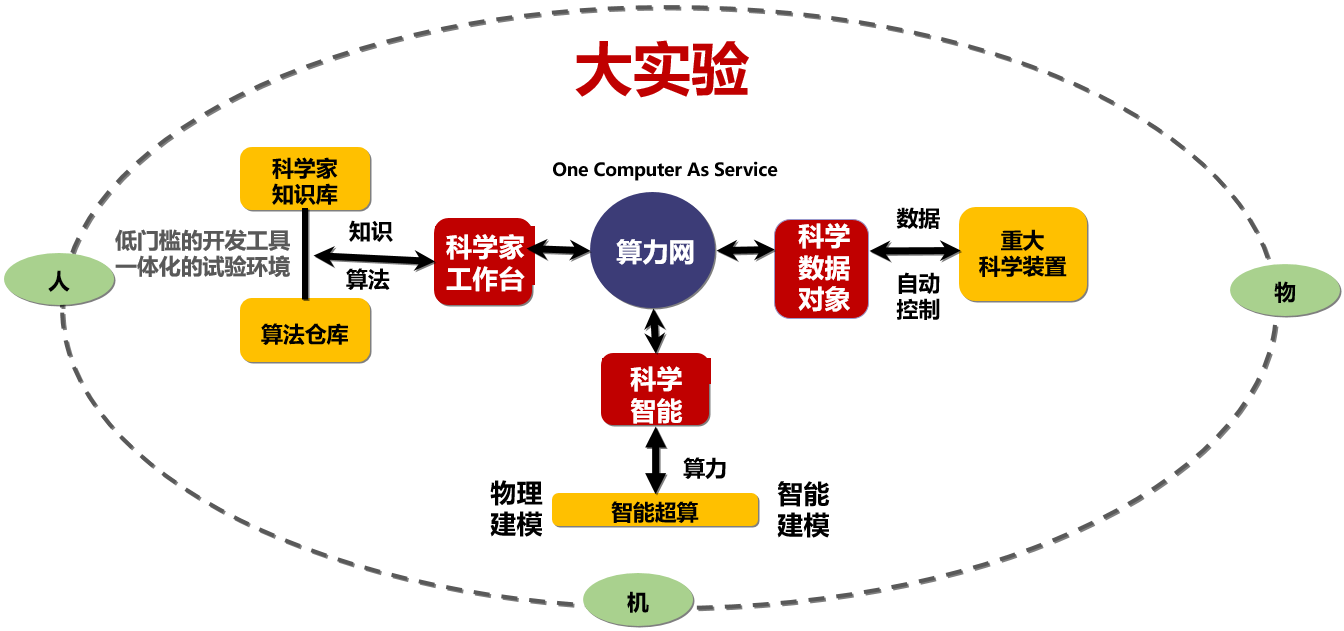
图3:服务重大科学发现的“大实验”
体现第五范式理念的“大实验”架构如图3,位于中间的算力网,是“人机物”三元世界的连接点;在“物”的维度,把重大科学装置提供科学数据的对象化,以备传输与处理;在“机”的维度,智能超算系统为科学智能方法提供计算支撑,把传统的物理建模手段,和增加的智能建模手段,融合在一个问题求解过程里。在“人”的维度,科学家的工作台建立起知识库、算法仓库、模型仓库,提供低门槛的开发工具和一体化的试验环境。它们加在一起就是“大实验”。
5.信息高铁算力网
第5层是信息高铁算力网,作为上层智能算法与重大应用的新型基础设施。ChatGPT大模型就是模型的基础设施化,可以用API调用的方式使用。如图4所示,算力网是给上层智能数据和智能驱动的计算范式提供的一个基础设施,跟互联网是不同的。互联网是基础的平台,TCP/IP实现了全球数据的互联互通, WWW(信息网)实现了全球信息的互联互通,而算力网是把算法组件、数据对象、算力容器三合一的基础设施,应用以算力网页的方式使用并网的算力站,算力网页可以同时对云、网络、算力服务质量进行软件定义。
计算所布局的信息高铁算力网实现六个核心技术:多云统一、站网分离、变租为用、网程抽象、单一计量、质量测度。网络底层的工作包括面向万物互联的宽带卫星网、工业5G网,原生地支撑算力基础设施的CENI试验网。信息高铁算力网的特征是高通量和低熵,其中高通量是针对用户表现,低熵是针对体系结构。

图4:信息网 vs 算力网
6.大数据分析与AI算法
第6层是大数据分析与AI算法,支撑上层的重大应用。在这方面对计算所的挑战是怎么把碎片化的众多算法创新凝聚成“稠密子图”,其中有三个关键词比较重要:云原生、广谱关联、X-数据。算法只有云化,AI模型只有服务化(MaaS),才能在信息高铁算力网上被作为组件调用,才能跟算力基础设施层勾连在一起,才能实现大数据、智能算法的规模产业化。计算所布局的天玑广谱关联大数据分析引擎必须云化,面向健康的智能算法、联邦模型也必须云化。广谱关联和X-数据是计算所在数据分析上有特色的科研工作。
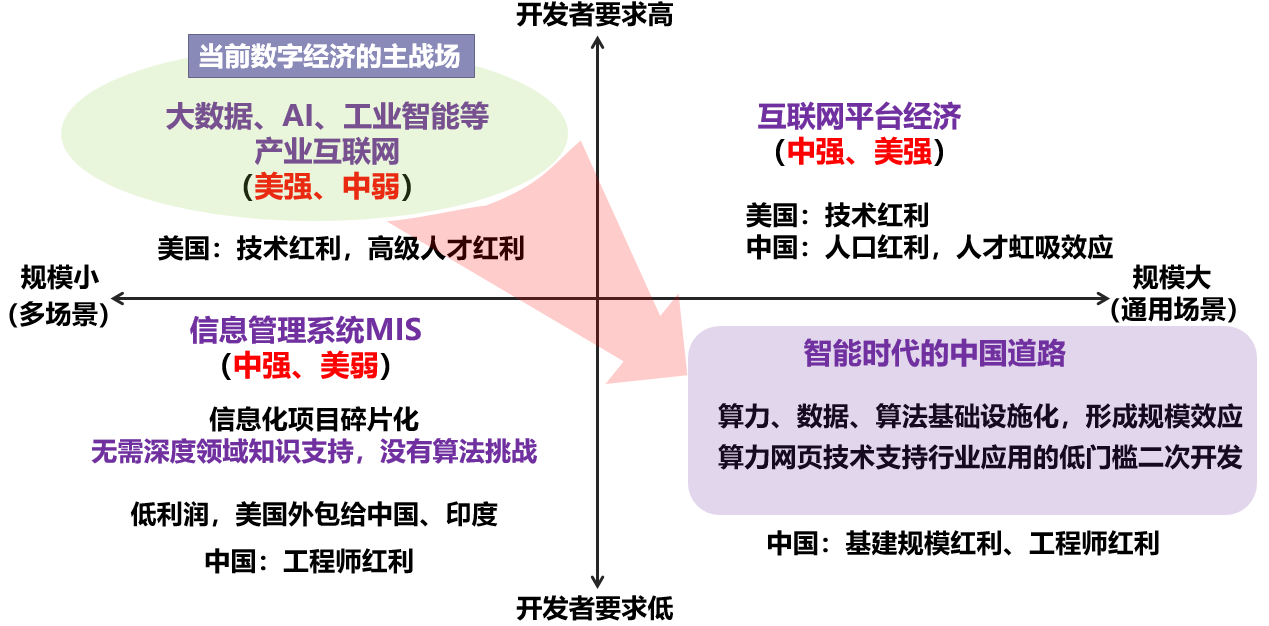
下面探讨一下解决我国产业数字化转型痛点问题的路径。图5的横坐标是问题的规模和场景,纵坐标是开发者要求,越往上对开发者要求越高,这两个维度是决定产业规模的核心要素。四个象限中,右上角的象限是互联网平台经济,中国和美国都强,美国是依靠技术红利,中国是依靠人口红利、人才虹吸效应。对角线的左下角象限是信息管理系统(MIS),是中国强、美国弱。信息化项目碎片化,而且无需深度领域知识支持,没有算法挑战,利润低,所以美国把这部分外包给中国和印度了。左上角的象限是当前数字经济的主战场,包括大数据、AI和工业智能,需要技术红利和高级人才红利,这部分是美国强、中国弱。美国有大量的高端人才,而中国是工程师总量大,高端人才少。对角线右下角的象限,可以成为智能时代的中国道路,即把算力、数据、算法基础设施化,形成规模效应,通过算力网页等技术支持行业应用的低门槛二次开发,利用中国的数字新基建规模红利和工程师红利,做大做强产业互联网。
7. 数据与智能驱动的重大应用
第7层是数据与智能驱动的重大应用,是计算技术发展的新驱动力,也是计算技术新体系的试验场。在安全领域,计算所的布局是从网络安全(网络关防),到信息安全(舆情/情报),再到智能算法安全,将来要形成智能算法安全的基础理论与关键技术体系。未来重大应用的建模对象,如权力运行、疾病的分子机理、主粮作物生长、社会舆论、军事对抗过程、工业生产流程等复杂系统,其数字建模需要新的理论与方法,这部分是技术难题。计算所目前布局的重大应用包括:智能宣传、智能情报、数字内容深伪检测、大数据监督、蛋白质人工设计等。
四、总结
信息技术要向5G、高铁、北斗学习,努力建立高水平自立自强的计算技术新体系。展望2035年,围绕系统熵建立起计算系统中不确定性的理论与方法是一个学术挑战;发展出通用Z级智能计算的新技术是一个工程技术挑战;实现算力新容器、数据对象、算法模型三位一体的新一代信息基础设施——算力网,将我国信息赋能的效率提高一个数量级,是一个应用技术挑战。
(根据孙凝晖院士在2023年计算所春季战略规划会上的报告整理)